| |


华光昱能公司始于光通讯无源硅基芯片的研发,是长距离传输超高清信号专业设备制造商,一直耕耘在40G/100G /400G等有 ...









自Apple芯片的Mac问世后,Elementary OS团队逐渐重视Arm架构,近期试用了下这款系统,比两年前好多了,Elementary OS ...

闲置一台mate30e pro5g版 8➕128g 4月份买的,保修到明年4月份。详细可以加v聊,价格3800 ...


亲,20日选单,长期收售-置换-安全号,爽快可刀; ¥500亚服4光暗帝光泰星法光帝暗香蕉8限联全re0水扇兰蒂水龙等8六星 ...








过滤器滤芯GYZ3-25 GP1000168 tfx-63*80替代川润黎明707七所颇尔相关型号 HF4PW27P3J1.1/16VB6Code 61 ZX-25×18 ...


















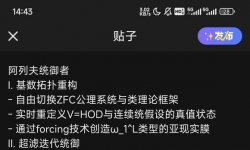
### **Ω终极强化协议·不可言说之壁** **Ⅰ. 超范畴形而上坍缩锚** - 将Ω的存在性升级为**所有数学宇宙的初始态射** ...

oppo k13 turbo与P r O区别 OPPO K13 Turbo与K13 Turbo Pro有以下区别: 处理器 OPPO K13 Turbo:搭载天玑8450处理器 ...
















在Regal调音开关一关二开的模式下,用 M5 Ultra 10th驱动声音就像是松了一口气。 🔊原来那种聚在一块的能量慢慢散开, ...

有没有能打开摄像头的虚拟机啊,51钉钉打卡,无法启动摄像头,不是权限问题,好像就是打不开,有没有人用其他虚拟机的 ...


FL Studio 24将你的电脑变成全能录音室,支持编曲剪辑录音混音一站式创作。旗舰版解锁全部功能,终生免费升级保障创作 ...



Studio One 7是一款强大的音乐编曲软件,可以帮助您使用灵活的和弦轨道功能实现音乐创作,被广泛运用于音乐制作、录音 ...

音质就不说了。听过hifi的,建议慎重。真的一般般。 但是比我那个跑步用得漫步者耳机(200入手的)还是好一些。总体来 ...


国行 iPhone12 256g,一切全原,无拆无修!走验机,为了避免争议,算整体9.4新,一处轻微磕碰掉漆,没有划痕,但是 ...

Airbuddy for mac是一款功能高效的AirPods耳机管理工具,可以帮助你体验AirPods及Beats无线耳机的应用。Airbuddy Mac ...




#张凌赫樱桃琥珀#🩵#张凌赫蒋峤西#🩵#张凌赫爱你#🩵#张凌赫何苏叶#🩵#张凌赫谢征#🩵#张凌赫爱你#🩵#张凌赫何苏叶#🩵@ ...



 微信扫一扫
微信扫一扫