|
VexyreCore
2022-9-7 15:04:07
显示全部楼层
| |








MacBook Pro 16 英寸(M3 Max,2023 年)评测:有史以来最强大的MacBook... ...









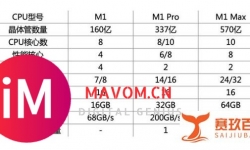
2023年苹果M1、M1 Pro、M1 Max芯片Macbook Air、MacBook Pro笔记本推荐... ...






watchOS 8.5 打破 Apple Watch Series 7 对许多用户的快速充电支持_百 ... ...
























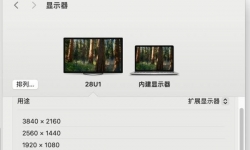

苹果macOS 15 Sequoia投屏功能 实现Mac上iPhone桌面管理 ...
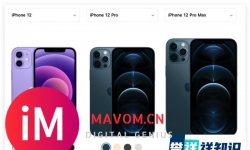
iPhone 12、 iPhone 12 Pro 、iPhone 12 Pro Max 的主要区别是什么... ...


iPhone 12 pro与iPhone 12 pro Max的区别有哪些?哪个更值得购买?_百度... ...


彭博社的 Mark Gurman 一直在分享有关苹果期待已久的 Siri 改革将包括和不包括哪些内容,Engadget 这条消息不只是在同 ...

26.4 的更新比最近几次更新更为重要,它会直接影响苹果产品线节奏、换机预期和生态功能落地。Ars Technica 这条消息不 ...
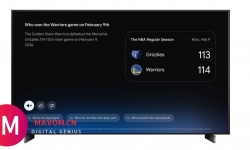
Google TV 即将上线由 Gemini 驱动的三项新功能,分别是视觉回答、深度解析和运动简报。相比一次常规功能更新,这次变 ...

OpenAI 正在对 Sora 进行产品整合。表面上看,这是一次旧服务下线;但更准确地说,这是一轮从 Sora 1 向 Sora 2 的迁 ...

Databricks 最近筹集了 50 亿美元资金,手握充足资源,正在通过收购进一步扩展其产品版图。此次收购的重点不只是“买 ...






# Firefox 中的拆分视图:两个并排的选项卡,就在您需要的地方 > 来源:Mozilla Blog | 2026-03-24T03:00:00+08:00 ...

> 来源:TechCrunch | 2026-03-24T04:42:41+08:00 这条消息刚出来时,很多人第一眼可能只会看到表面更新。但如果往 ...

> 来源:TechCrunch | 2026-03-24T02:00:45+08:00 TechCrunch 最新披露的这条消息,把注意力拉回到“苹果 接下来 ...

> 来源:Ars Technica | 2026-03-24T05:19:51+08:00 这条消息刚出来时,很多人第一眼可能只会看到表面更新。但如果 ...
> 来源:Mozilla Blog | 2026-03-24T03:00:00+08:00 Mozilla Blog 最新披露的这条消息,把注意力拉回到“软件工具 ...

> 来源:The Verge | 2026-03-24T03:49:11+08:00 ![图片来源:The Verge] 放在今天的科技新闻里,这条不一定最炸, ...

[md]> 来源:GitHub Blog | 2026-03-24T00:00:00+08:00 ![图片来源:GitHub Blog]
来源:Ars Technica | 2026-03-24T02:34:59+08:00 图片来源:Apple Ars Technica 最新披露的这条消息,把注意力拉 ...
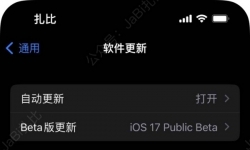

苹果的A12Z和A14到底哪个更强?iPad Air 4和iPad Pro 2020哪个更值得入手... ...

M1还是A12Z,有必要买iPad Pro 2021吗?还是直接买iPad Pro 2020?_百度... ...
















 微信扫一扫
微信扫一扫