| |
| |

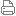
# Firefox 中的拆分视图:两个并排的选项卡,就在您需要的地方 > 来源:Mozilla Blog | 2026-03-24T03:00:00+08:00 ...

> 来源:TechCrunch | 2026-03-24T04:42:41+08:00 这条消息刚出来时,很多人第一眼可能只会看到表面更新。但如果往 ...

> 来源:TechCrunch | 2026-03-24T02:00:45+08:00 TechCrunch 最新披露的这条消息,把注意力拉回到“苹果 接下来 ...

> 来源:Ars Technica | 2026-03-24T05:19:51+08:00 这条消息刚出来时,很多人第一眼可能只会看到表面更新。但如果 ...
> 来源:Mozilla Blog | 2026-03-24T03:00:00+08:00 Mozilla Blog 最新披露的这条消息,把注意力拉回到“软件工具 ...

> 来源:The Verge | 2026-03-24T03:49:11+08:00 ![图片来源:The Verge] 放在今天的科技新闻里,这条不一定最炸, ...

[md]> 来源:GitHub Blog | 2026-03-24T00:00:00+08:00 ![图片来源:GitHub Blog]
来源:Ars Technica | 2026-03-24T02:34:59+08:00 图片来源:Apple Ars Technica 最新披露的这条消息,把注意力拉 ...

苹果的A12Z和A14到底哪个更强?iPad Air 4和iPad Pro 2020哪个更值得入手... ...

M1还是A12Z,有必要买iPad Pro 2021吗?还是直接买iPad Pro 2020?_百度... ...








































齐齐哈尔斗山NHP8000机床钣金防护罩 齐齐哈尔斗山NHP8000钣金防护罩创新设计:庆云金恒兴的匠心突破 在重型数控机床领 ...






用了三个月的AirPods Pro不幸掉了右耳,找不到了。准备小黄鱼买一只二手的配一对。 看到好多卖家都有大批量的二手airp ...




最新版chrome在启用--force-renderer-accessibility浏览页面时会崩溃, 错误代码:STATUS_BREAKPOINT ...



救救孩子吧 iPad密码错误太多次停用了 显示连接iTunes 我按照百度流程连接了 点更新提示我iTunes不是最新版本需要更新 ...

✨2025 美国产业用布及纺织品展,Advanced产业布年度盛会来袭,不可错过,冲鸭! 各位产业布行业的从业者们👋,今天 ...

蝙蝠最新版本Android&iOS 3.5.0已上线(可至官网下载https://www.batchat.com) 主要更以下功能: 一、新增水印相机功 ...




苹果在上周发布了iPhone 17e和MacBook Neo等新品,但是备受期待的HomePod mini以及新款Apple TV一直没有出现,现在有 ...





 微信扫一扫
微信扫一扫