| |





以下是配置: 型号:蛟龙16Pro5060 颜色:璃光白 CPU:R9-8940HX(16核心32线程) 单核MAX主频可达5.4GHz“Zen4”架构 ...

下载链接:https://www.huix8.com/youer/kpbk/50166.html BBC科技启蒙经典动画片《万物运转的秘密》 【批量下载】万 ...


﹌💯清盘钜惠行动中💯 ﹌ 🌈——南漳碧桂园——🌈 🔥最后席位 错过再难得 🏡 好房靠抢❗火爆递减 ☎️抢购热线:15671 ...

有一个免费学习ps修图、AE摄影后期、CAD、室内设计、抖音快手短视频剪辑、风景摄影,日系插画,影视广告制作的群,感 ...

双面神无限觉醒➕配件呢?比四件套厉害多了吧!这么大卖点看不到。。和紫母体16v16。只有这种双面神有胜算。。只要母 ...












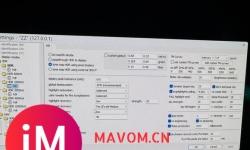
首发入的32ucdm,也有一会了,分享下观看hdr影片的一些参数,用的是potplayer+madvr(具体版本是206还是207不太记得了 ...





Just in from the TFW team at SDCC 2025 we have pics from Hasbro booth preview night for your viewing pleasure! ...

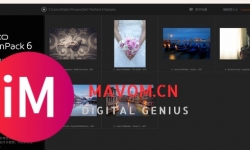
DxO FilmPack mac/win版支持在相机RAW文件上实时预览胶片效果,无需后期繁琐调整。例如,摄影师在Capture One中导入尼 ...


由Prineside 开发制作的简易风格塔防游戏《无限塔防2(Infinitode 2)》官宣了从10月14日更新最新的1.8.4版本之后,该作 ...


这几天贴吧和论坛里的讨论,吹也好喷也罢 说白了还是粉丝圈及周边相关游戏圈内的一个评价罢了。 方块这种小众平台, ...

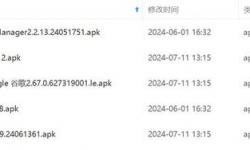
三星watch最新版app,提取自三星手机,小米11u使用正常。版本见图。今早打开手机上的app,进去不,说要升级,升级谷歌 ...
奈飞高级4k会员,一人跳车,还有1个车位,月付15元,来长期固定的,必须长期稳定的!自用账号,以稳定开车好几年了! ...

职业介绍 第一次进入游戏, 先创建性别和职业指令示例: 女道士, 男道士, 女剑士, 男剑士 ♐剑士: 中血 / 高物攻 / 物防 ...



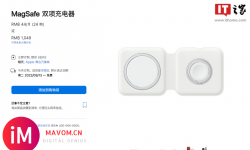
iPhone 14 发布会后,苹果官网下架并停产 649 元的 Apple Watch 磁力充... ...



今天凌晨的发布会上,苹果正式推出了第三代AirPods无线耳机,采用全新的涉及,升级了全新的驱动单元,支持动态头部追 ...







 微信扫一扫
微信扫一扫