| |







单项选择题 1、37. – Could I borrow your car for a few days?- ______ 00001. Yes, go on.00002. Sure, here ...







今年M4 加A18 全系8G Mac 12运存起步 iPad mini. Se4 iPhone 16全部A18芯片 pro A18pro Mac mini air. M4 还有m4 ma ...


[恋爱得分][池山田刚][東立][1-7完]高清原画漫画下载 百度网盘下载 https://pan.baidu.com/s/1JcLR6z_DiZFpZkgX8pSSvQ ...



青岛非开挖管道修复/158-988-22220;管道置换电话158-988-22220 青岛畅通快洁管道疏通清洗施工:大型高压清洗车,高压 ...

高密管道清淤-156-6652-1215;井室喷涂管道疏通-管道修复置换0532-6663-5353 信息推荐畅通快洁管道工程有限公司, 是 ...

Iphone14Pro 3倍变焦放大后摄像头花屏怎么办啊!!在九机网买的,今天去问了人家说要返厂维修!!!怎么办啊这个,1月 ...


李沧抽污水-非开挖管道修复-131-7653-7327;联系电话0532-8888-9866 公司是一家管道高压清洗、下水道疏通、化粪池清理 ...



有需要入手和想了解的可以看一下 4-13系列全都有 现在全新13全系列各个版本都在掉价 不管你是在等国行还是港版还是美 ...






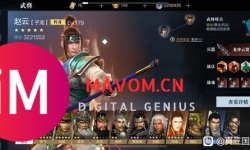
厂房地址:成绵高速青白江出口一汽解放对面 面积区间:1300-6000㎡可选 户型结构:高品质单层钢结构、全新独栋分层框 ...

今天实在忍不住把iPhone8从iOS12.4升到iOS15.3.1,万万没想到耗电还比以前慢了,更流畅了,是我的错觉吗。还以为升了 ...




出租,出售康远小区6楼50平米,简单装修,带家具。售价5.5万元。租金6000元。13948184099 另面包车包车出租! ...








线基是图一的 线是银98%铜1.9%金0.1%,线径是1mm 由xone代工,如图二所示 整体是条女毒线,支持试听 🐟号:skyline2 ...



下载链接:https://www.huix8.com/youer/seyy/63205.html 《The Princess Rules 公主的规则》1-3 册 多格式文本 + 音 ...








南京硬盘数据恢复_客户8GB U盘不识别数据恢复成功 客户单位:客户8GB U盘不识别数据恢复成功 设备:台电8GB U盘 故障 ...



MacBook Pro 开机屏幕不亮,USB-C 接口无响应维修 来源:麦克雷维修案例 | 2026-03-09 图片来源:麦 ...



⚠️10小几万,15款宝马750Li黑色黄内 无匙进入 抬头显示 一健启动 座椅按摩 多功能方向盘 4电吸门 电尾门 哈曼卡顿L7 ...

介绍1人奖励400元金现红包🧧 介绍5人奖励iphonex一部 介绍10人奖励iPhone12一部 介绍20人励奖新款iPhone13pro一部 ...

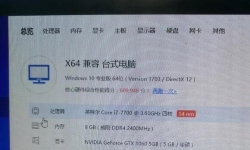
想配一个电脑玩魔兽世界,游戏的要求如图 求大神给个配置啊 最好5千以内 之前很喜欢mac mini m2,觉得小巧方便,还能 ...


蓝色笑脸airpods苹果蓝牙无线耳机套3挂环适用透明airpods2保护套~ http://www.dzsw42.com/product-item-15.html ...







 微信扫一扫
微信扫一扫